1. 概述 字符串函数是用于处理和操作字符串(文本)数据的函数。不同的数据库提供的字符串函数可能会有所不同,但基本功能通常类似。本文介绍 Spark SQL 中的字符串函数,以下按照基本字符串操作、字符串查找与截取、替换、转换和逻辑判断等用途逐项介绍。 2. 函数列表2.1. 基本字符串操作用途 | 函数 | 举例 | 结果 | 返回字符串的长度 | length()/len() | length('ABC DE') | 6 | 将英文字符串转为首字母大写 | initcap() | initcap('ABC DE') | Abc De | 将英文字符串转为小写 | lcase()/lower() | lcase('ABC'); lower('ABC') | abc | 将英文字符串转为大写 | ucase()/upper() | ucase('abc'); upper('abc') | ABC | 将字符串顺序反转 | reverse() | reverse('abc') | cba | 字符串拼接 | concat(str1,str2) | concat('Spark', 'SQL') | SparkSQL | str1 || str2 | 'Spark' || 'SQL' | SparkSQL | 用分隔符拼接字符串或数组 | concat_ws(sep[, str | array(str)]+) | concat_ws('-', 'Spark', 'SQL') | Spark-SQL | 返回字符串重复对应数值次数后的新字符串 | repeat(str, n) | repeat('ABC', 2) | ABCABC | 在字符串左侧填充指定字符,使字符串达到指定的长度 | lpad(str, len[, pad]) pad省略时填充空格 | lpad('hi', 5, '?') | ???hi | 在字符串右侧填充指定字符,使字符串达到指定的长度 | rpad(str, len[, pad]) | rpad('hi', 5, '??') | hi??? |
*所有函数内的[ ]为可省略参数。 2.2. 字符串查找与截取用途 | 函数 | 举例 | 结果 | 查找子字符串在字符串中的位置
| locate(substr, str[, pos]) pos指定起始查询位置,省略时代表1 | locate('n','Ann',3) | 3 | instr(str, substr) | instr('Ann','n') | 2 | find_in_set(str, str_array) 被查询字符串需要是以逗号隔开的字符串。 | find_in_set('ab','abc,b,ab,c,def') | 3 | 从左侧开头处截取固定长度字符串 | left(str, len) | left('Spark SQL', 3) | Spa | 从右侧结尾处截取固定长度字符串 | right(str, len) | right('Spark SQL', 3) | SQL | 从指定起始位置截取字符串,可指定长度 | substr(str, pos[, len]) ; substring(str, pos[, len]) | substring('123abcABC', 2, 3); substr('Spark SQL', -3) | 23a; SQL | 截取从字符串的开始位置到指定分隔符出现的第 n 次位置之间的子字符串 | substring_index(str, delim, n) n为正数,从左向右截取;为负数则从右向左截取 | substring_index('a.b.c.d.e', '.', -2) | d.e | 移除字符串开头(左侧)的空格 | ltrim(str) trim(LEADING FROM str) | ltrim(' Spark SQL') | Spark SQL | 移除字符串结尾(右侧)的空格 | rtrim(str) trim(TRAILING FROM str) | rtrim('Spark SQL ') | Spark SQL | 移除字符串开头和结尾(左右两侧)的空格 | trim(str) trim(BOTH FROM str) btrim(str) | trim(' Spark SQL ') | Spark SQL | 移除字符串开头和结尾(左右两侧)的指定字符 | trim(trimStr FROM str) | trim('*' from '*AB*C**') | AB*C | btrim(str, trimStr) | btrim('SSparkSQLS', 'SL') | parkSQ | 截取URL里指定部分 | parse_url(url, part[, key]) | parse_url('http://spark.apache.org/path?query=1', 'QUERY', 'query') | 1 | 以单个或多个字符分割字符串。返回数组,配合数组函数可提取子字符串 | split(str, regex[, limit]) 分隔符支持正则表达式,limit指定分割后元素数,省略时代表全部拆分 | split('A1B2C','\\d'); split('A-B-C','-')[1] | [A, B, C]; B | 返回正则匹配到的第一个子串 | regexp_extract(str, regexp[, idx]) | regexp_extract('*A1B2*C3**','[A-Z]+',0) | A |
2.3. 字符串替换用途 | 函数 | 举例 | 结果 | 替换所有匹配到的字符 | replace(str, search[, rep]) rep省略时移除所有匹配到的字符。 | replace('ABCabc', 'abc', 'DEF') | ABCDEF | 多字符替换 | translate(str, from, to) 将from中的每个字符替换为to中相应字符。若from比to字符串长,from中比to多出的字符将会被删除。 | translate('AaBbCc', 'abc', '123'); translate('AaBbCc', 'abc', '12') | A1B2C3; A1B2C | 替换固定位置字符,可指定替换长度 | overlay(str, rep, pos[, len]) | overlay('Spark SQL','+',2,5); overlay('Spark SQL' PLACING '+' FROM 2 FOR 5) | S+SQL | 正则匹配替换所有匹配到的字符 | regexp_replace(str, regexp, rep) | REGEXP_REPLACE('*A1B2*C3**','[\\d\*]','') 把所有数字和*去除 | ABC |
2.4. 字符串转换用途 | 函数 | 举例 | 结果 | 将其他类型转换为字符串 | string() | string(123) | 123 | cast( expr as string) | cast(123 as string) | 123 | 转换为ASCII字符 | char(expr) / chr(expr) | char(65) | A | 将字符串按照指定字符集进行编码处理 | encode(str, charset) | encode('abc', 'utf-8') | abc | 将编码后的数据解码 | decode(bin, charset) | decode(encode('abc', 'utf-8'), 'utf-8') | abc | 对数据进行掩码以隐藏敏感信息 | mask(str[, upperChar, lowerChar, digitChar, otherChar]) 默认字母:X(大写)/x(小写);数字:n | mask('AbCD123-@$#'); mask('AbCD123-@$#', NULL, 'q', 'd', 'o') | XxXXnnn-@$#; AqCDdddoooo | 将二进制数据编码为 Base64 字符串 | base64(bin) | base64('Spark SQL') | U3BhcmsgU1FM | Base64 字符串解码 | unbase64(str) | unbase64('U3BhcmsgU1FM') | Spark SQL | URL 编码 | url_encode(str) | url_encode('https://spark.apache.org') | https%3A%2F%2Fspark.apache.org | URL 解码 | url_decode(str) | url_decode('https%3A%2F%2Fspark.apache.org') | https://spark.apache.org |
2.5. 字符串逻辑判断用途 | 函数 | 举例 | 结果 | 字符串模糊匹配 (结合通配符使用) | like 区分大小写 | 'Spark' like '%Park' | false | ilike 不区分大小写 | ilike('Spark', '_Park') | true | 字符串模糊匹配 (结合正则表达式使用) | rlike | 'PURE&MILD' rlike '[A-Z]+\&[A-Z]+' | true | 判断字符串是否以...开头 | startswith(str, substr) | startswith('Spark SQL', 'SQL') | false | 判断字符串是否以...结尾 | endswith(str, substr) | endswith('Spark SQL', 'SQL') | true |
更多Spark函数及用法请参考官方文档 https://spark.apache.org/docs/latest/api/sql/#_1
3. 应用案例案例描述: 文本字段“Sprint”,需要分别提取出: 第一项:中间部分“排期”,由数字和字母组成的6至8位字符串; 第二项:括号里的内容“测试版本”; 第三项:基于“测试版本”推算出“正式版本”(逻辑:最后一个小数点后数字为小版本号,为0时前面部分即为正式版本号,不为0时中间数字加1)。 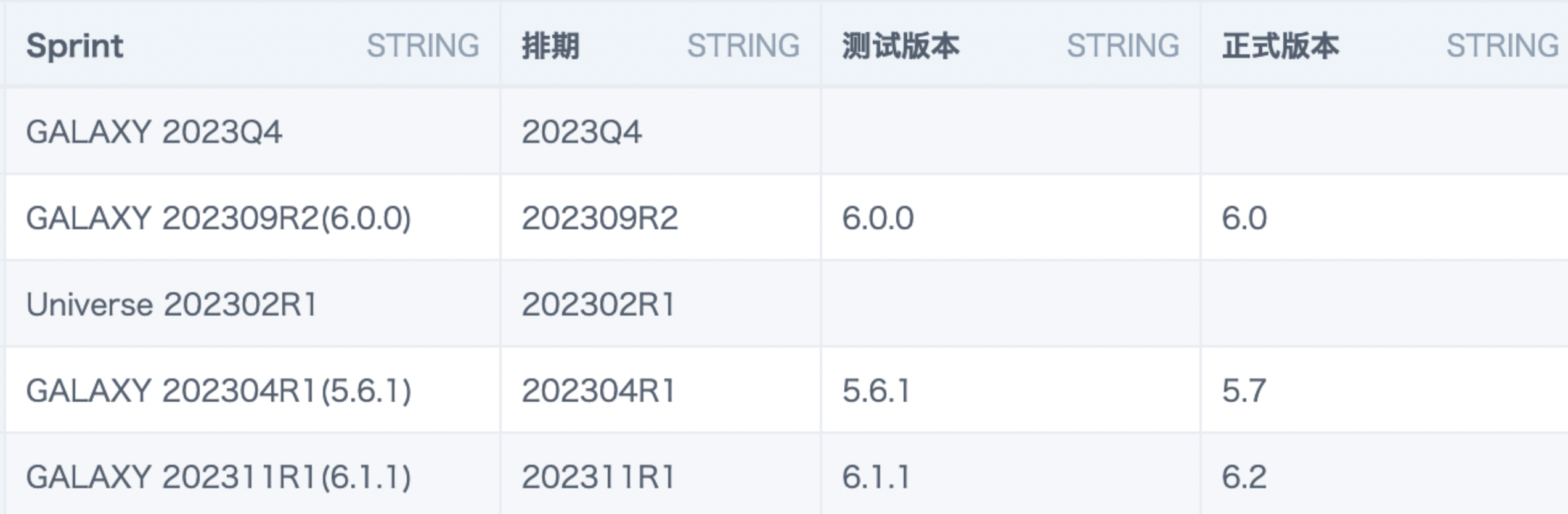
实现方式: 第一项:「排期」由数字和字母组成的6至8位字符串。实现方式(任选其一): 1. substr([Sprint],instr([Sprint],' ')+1,8) --判断第一个空格位置,从空格后截取8位字符
2. left(overlay([Sprint],'',1,instr([Sprint],' ')),8) --去除空格和前面字符,截取左侧8位
3. regexp_extract([Sprint], '(\\d{4,6}\\w{2})', 1) --正则提取4~6位数字和后面2个字符
4. element_at(flatten(sentences([Sprint])),2) --按照特殊符号拆分成数组后取第2个元素
第二项:「测试版本」为括号里带.的数字串。实现方式(任选其一): 1. regexp_extract([Sprint], '(\\d\\.\\d{1,2}\\.\\d)', 1) --正则提取带.的数字串
2. case when instr([Sprint],'(')>0 then replace(substr([Sprint],instr([Sprint],'(')+1),')') end --判断前括号(位置,截取后面字符,去掉)后括号
3. case when [Sprint] like '%(%' then substring_index(translate([Sprint],'()','-'),'-',-1) end --同上
4. element_at(flatten(sentences([Sprint])),3) --按照特殊符号拆分成数组后取第2个元素
第三项:「正式版本」测试版本最后一个小数点后数字为小版本号,为0时前面部分即为正式版本号,不为0时中间数字加1。实现方式: case when right([测试版本],1)=0 then substring_index([测试版本],'.',2)
else concat(left([测试版本],2),int(substr(substring_index([测试版本],'.',2),3)+1))
end
|






