| 一、ETL中间结果缓存作用 ETL 中间结果缓存是当 ETL 相对较复杂时(至少包含两个输出数据集且超过设置的复杂度阈值),通过启用该配置,系统会自动将中间运算结果进行缓存以加速整个 ETL 的运行效率。
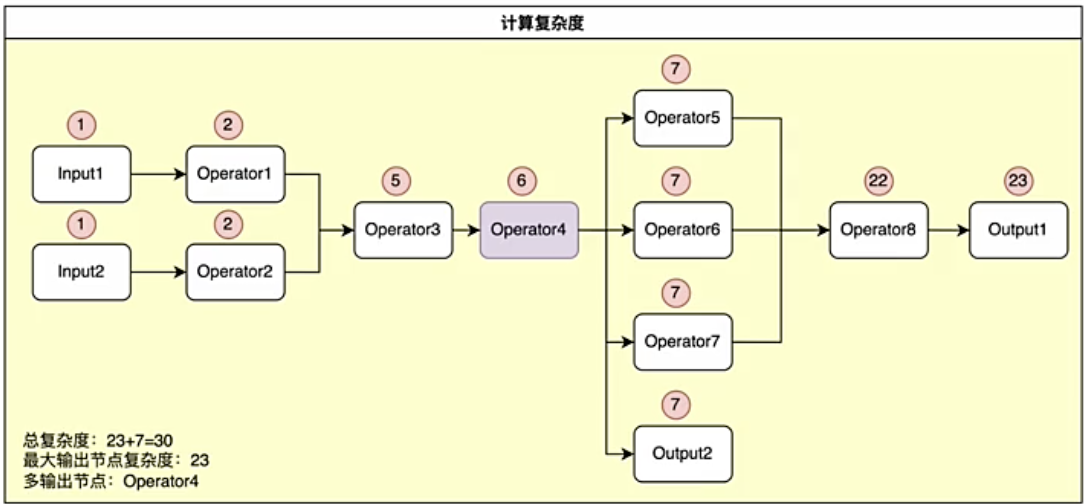
二、ETL中间结果缓存阈值计算逻辑 如下图情况 1)第一列的input节点,因为它本身是没有计算逻辑的,所以input1和input2计算复杂度为1 2)第二列的Operator节点,因为它有了计算逻辑,但是因为前面的input节点没有,所以Operator1和Operator2计算复杂度只是在input的计算复杂度之上再加1,即为2 3)第三列的Operator节点,因为它本身有计算逻辑,所以复杂度为1,又因为前面有两个有计算逻辑的复杂度为2的节点,所以Operator3即是前面两个节点之和加上它本身的复杂度,即2+2+1=5 4)第四列的Operator节点,因为它本身有计算逻辑,所以复杂度为1,又因为前面有一个有计算逻辑的复杂度为5的节点,所以Operator4即是前面一个节点复杂度加上它本身的复杂度之和,即5+1=6 5)第五列的Operator节点,Operator5,Operator6,Operator7都是因为其本身有计算逻辑,所以复杂度为1,又因为前面有一个有计算逻辑的复杂度为6的节点,所以Operator5,Operator6,Operator7即是前面一个节点复杂度加上它本身的复杂度之和,即6+1=7; Output2因为其后面没有计算节点了,因为它本身有计算逻辑,所以复杂度为1,又因为前面有一个有计算逻辑的复杂度为6的节点,所以Output2即是前面一个节点复杂度加上它本身的复杂度之和,即6+1=7,且终止在7 6)第六列的Operator节点,因为它本身有计算逻辑,所以复杂度为1,又因为前面有3个有计算逻辑的复杂度为7的节点,所以Operator8即是前面3个节点复杂度加上它本身的复杂度之和,即7+7+7+1=22 7)第七列的Output节点,因为它本身有计算逻辑,所以复杂度为1,又因为前面有一个有计算逻辑的复杂度为22的节点,所以Output1即是前面一个节点复杂度加上它本身的复杂度之和,即22+1=23 所以总复杂度,即Output1和Output2计算复杂度之和,即23+3=30
三、ETL中间结果缓存阈值调整可能会带来的影响 1、提高阈值的影响 1.1)如果把 100 提高到 150 或 200,可能带来的影响: 原来会拆分的部分 ETL,可能不再拆分; 中间缓存次数会变少; 磁盘/临时表落地可能减少; 但单次 Spark 任务会更重,单链路内存、shuffle、计算压力更集中; 对复杂 ETL 来说,可能更容易出现长尾、超时、OOM、stage failure; 1.2)例子: 一个 ETL 有多路关联、聚合、输出,系统评估复杂度是 120。 阈值是 100:120 > 100,系统会拆分,先把一部分结果缓存下来,再继续后面的计算 阈值提高到 150:120 <= 150,系统不拆分了,整条链一次跑完 1.3)这时可能出现两种结果: 如果这个 ETL 其实不大,取消拆分后反而更快,因为少了中间落盘 如果这个 ETL 很吃资源,取消拆分后可能更容易把 driver / executor 压爆,报 Job aborted due to stage failure、超时或内存错误 2、降低阈值的影响 2.1)如果把 100 降到 80 或 60,可能带来的影响: 更多 ETL 会被拆分; 中间缓存次数会增加; 单次 Spark 任务压力会变小; 某些复杂 ETL 会更稳定; 但整体执行链路可能变长,落盘变多,IO 增加,反而可能变慢; 2.2)例子: 还是上面那个复杂度 120 的 ETL。 阈值是 100:会拆分 阈值降到 60:会拆得更多,甚至多段拆分 2.3)这时常见结果是: 好处:每一段更轻,复杂 join/聚合不容易一次性把资源吃满 代价:每段之间要写中间结果,可能增加存储占用、临时文件、整体时长 3、总结 3.1)提高阈值:偏性能,少拆分,但风险是重任务更重 3.2)降低阈值:偏稳定,易拆分,但代价是中间缓存更多、可能更慢 四、参考文档 1)ETL 中间结果缓存:https://docs.guandata.com/product/bi/etl-advanced-setting#ETL-%E4%B8%AD%E9%97%B4%E7%BB%93%E6%9E%9C%E7%BC%93%E5%AD%98 |