最近实践|如何判断数据库的原始字段,被哪些卡片新建计算字段引用
适用产品:观远 BI
适用版本:6.6 以上
简介:
在数据库治理、字段下线评估和模型排查场景中,经常会遇到一个问题:某个原始字段在 BI 里是否已经被卡片中的新建计算字段引用了。如果完全依赖人工逐个点开卡片检查公式,效率较低,也很难持续复用。
这次实践基于元数据库中的 data_source、card、page_card_rel、page、user、field 等表,先识别卡片中的计算字段,再从计算公式里拆出被引用的原始字段,最终生成一张“原始字段 - 新建字段 - 卡片 - 页面”映射明细表,并搭建一个支持筛选查询的 Demo 页面。
最终效果是:用户可以按“数据集名称”和“原始字段名称”进行筛选,快速定位某个原始字段目前被哪些卡片的新建字段引用,适合数据库字段治理、模型梳理和上线前影响排查。
涉及数据集:
本次方案使用 6 个元数据输入数据集和 1 个 ETL 输出数据集。
1、元数据输入数据集
元数据库只读账号的获取方式,可直接参考帮助中心文档:
本次实践中,输入数据集均直接读取元数据库原表,不在输入数据集层做任何加工,后续逻辑统一放在 ETL 中处理。
本次实际使用到的元数据输入如下:
card元数据:识别卡片信息、卡片所属数据集、卡片中的列定义和计算字段公式page_card_rel:建立卡片与页面的关联关系页面信息表(page):补充页面名称用户基础信息表(user):补充卡片创建人数据集字段信息表(field):识别原始字段、别名和普通字段口径元数据_data_source_新建_20260326_1841:回查数据集基础信息
2、ETL 输出数据集
ETL 输出的是一张用于查询和展示的宽表,保留字段如下:
数据集名称原始字段名称新建的字段名称卡片名称计算公式页面名称卡片创建人
本次输出数据集名称:元数据_原始字段被卡片新建字段引用_输出_20260401
数据处理:
1、数据来源说明
这次方案的核心思路是:先从 card 元数据中识别卡片里的新建计算字段,再把计算公式中引用到的字段名拆出来,再与 field 表中的原始字段做匹配,最后补齐页面、创建人和数据集信息。
因为输入数据集层不做处理,所以整个血缘链路清晰,后续如果环境变化,只需要替换元数据库连接即可。
2、新建 ETL 并引入输入数据集
本次 ETL 采用“输入数据集 -> SQL 节点 -> 输出数据集”的标准链路。6 个元数据输入节点直接接入 ETL,不做中间加工;核心逻辑集中在 SQL 节点里统一完成。
- ETL 名称:
元数据_原始字段被卡片新建字段引用_ETL_20260401
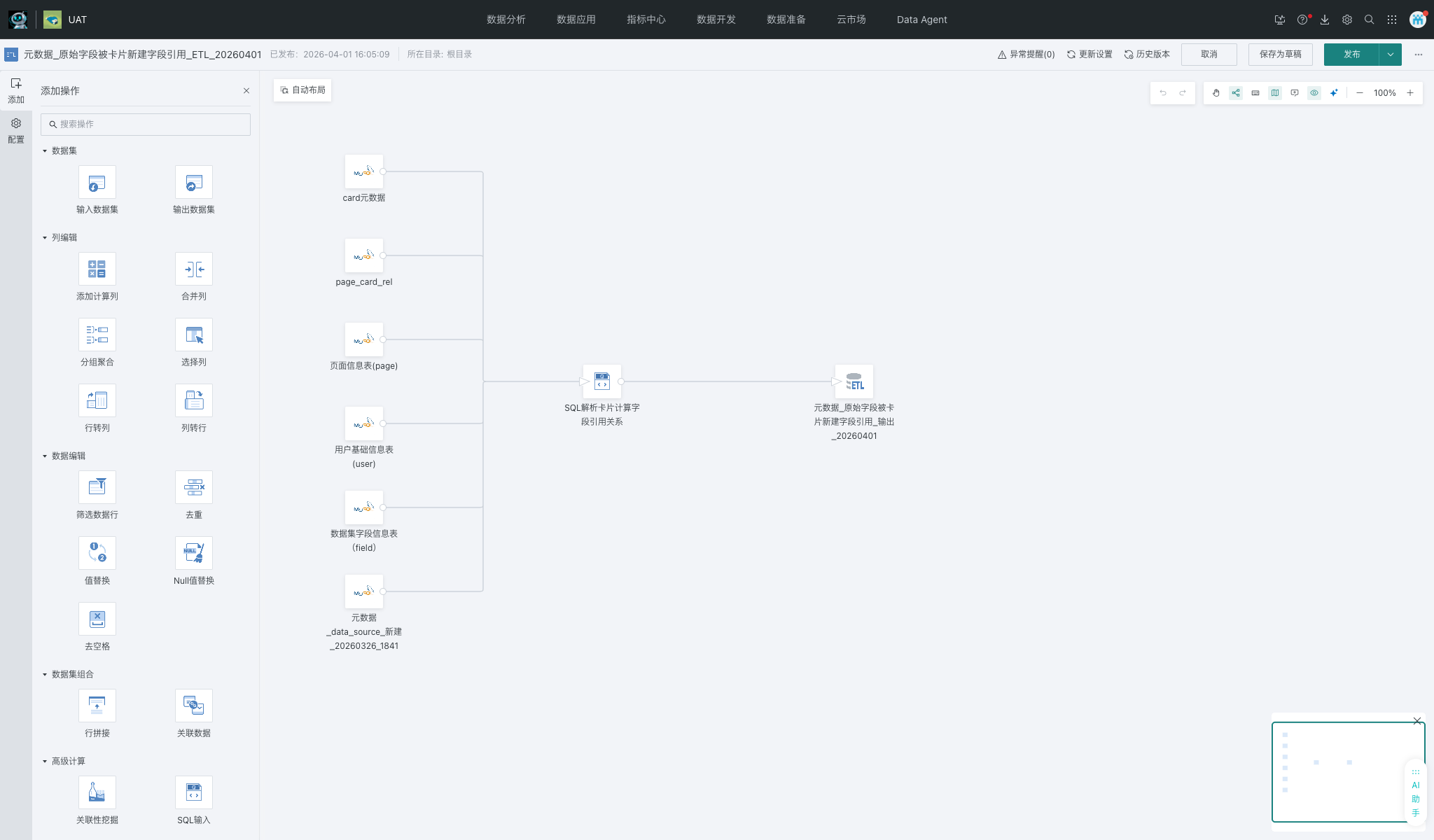
3、提取计算字段并解析原始字段引用关系
本次 SQL 节点主要做了三件事:
- 从
card 元数据中解析卡片列定义,识别出有公式的新建字段
- 将公式中的
[] 字段引用拆分成候选字段名
- 将候选字段名与
field 表中的普通字段、字段别名进行匹配,识别出真正的原始字段
本次实际使用的 SQL 如下,已在 ETL 中添加注释:
-- 识别被卡片新建计算字段引用的原始字段
WITH card_calc AS (
SELECT
c.cd_id,
c.p_id,
c.ds_id,
c.u_id,
c.name AS card_name,
col.name AS calc_field_name,
col.formula AS calc_formula
FROM input1 c
LATERAL VIEW explode(
from_json(
get_json_object(c.ds_info, '$.columns'),
'array<struct<name:string,formula:string,dsId:string,level:string>>'
)
) ex AS col
WHERE coalesce(c.is_del, 0) = 0
AND col.formula IS NOT NULL
AND trim(col.formula) <> ''
AND (col.dsId IS NULL OR trim(col.dsId) = '')
),
raw_tokens AS (
SELECT
cc.cd_id,
cc.p_id,
cc.ds_id,
cc.u_id,
cc.card_name,
cc.calc_field_name,
cc.calc_formula,
trim(token) AS raw_field_candidate
FROM card_calc cc
LATERAL VIEW explode(
split(
replace(replace(cc.calc_formula, '[', '|||'), ']', '|||'),
'\|\|\|')
) ex AS token
WHERE trim(token) <> ''
),
base_fields AS (
SELECT DISTINCT
ds_id,
`字段名, 不可修改` AS field_name,
coalesce(alias_name, '') AS alias_name
FROM input5
WHERE coalesce(is_del, 0) = 0
AND (formula IS NULL OR trim(formula) = '')
)
SELECT DISTINCT
coalesce(ds.name, rt.ds_id) AS `数据集名称`,
bf.field_name AS `原始字段名称`,
rt.calc_field_name AS `新建的字段名称`,
rt.card_name AS `卡片名称`,
rt.calc_formula AS `计算公式`,
coalesce(pg.name, '') AS `页面名称`,
coalesce(usr.name, '') AS `卡片创建人`
FROM raw_tokens rt
JOIN base_fields bf
ON rt.ds_id = bf.ds_id
AND (rt.raw_field_candidate = bf.field_name OR rt.raw_field_candidate = bf.alias_name)
LEFT JOIN input2 rel
ON rt.cd_id = rel.cd_id
AND coalesce(rel.is_del, 0) = 0
LEFT JOIN input3 pg
ON coalesce(rel.pg_id, rt.p_id) = pg.pg_id
AND coalesce(pg.is_del, 0) = 0
LEFT JOIN input4 usr
ON rt.u_id = usr.u_id
AND coalesce(usr.is_del, 0) = 0
LEFT JOIN input6 ds
ON rt.ds_id = ds.ds_id
AND coalesce(ds.is_del, 0) = 0
WHERE rt.raw_field_candidate <> ''
关键说明:
card.ds_info.columns 中保存了卡片字段定义,本次通过 from_json + explode 拆出每个字段- 只保留
formula 非空且 col.dsId 为空的字段,用来识别卡片中新建的计算字段
- 通过替换
[、] 再 split 的方式,从公式里提取字段引用片段
- 使用
field 表中的普通字段/别名做匹配,避免把新建字段再次误判为原始字段
- 通过
page_card_rel + page + user + data_source 回填页面、创建人和数据集信息
4、输出结果宽表
ETL 输出后的字段结构如下:
数据集名称:被卡片引用的数据集名称原始字段名称:被新建计算字段引用的原始字段新建的字段名称:卡片中新增的计算字段名称卡片名称:当前命中的卡片名称计算公式:新建字段对应的计算公式页面名称:卡片所在页面名称卡片创建人:卡片创建人
5、ETL 结果示意
本次 ETL 最终产出了一张“原始字段引用计算字段明细表”,可直接作为 Demo 页面的数据源。
6、ETL 逻辑导出附件
这里可以点击下载 ETL 的 zip 文件,在 ETL 里导入即可。文件名:原始字段引用计算字段_ETL_20260401.zip
看板搭建:
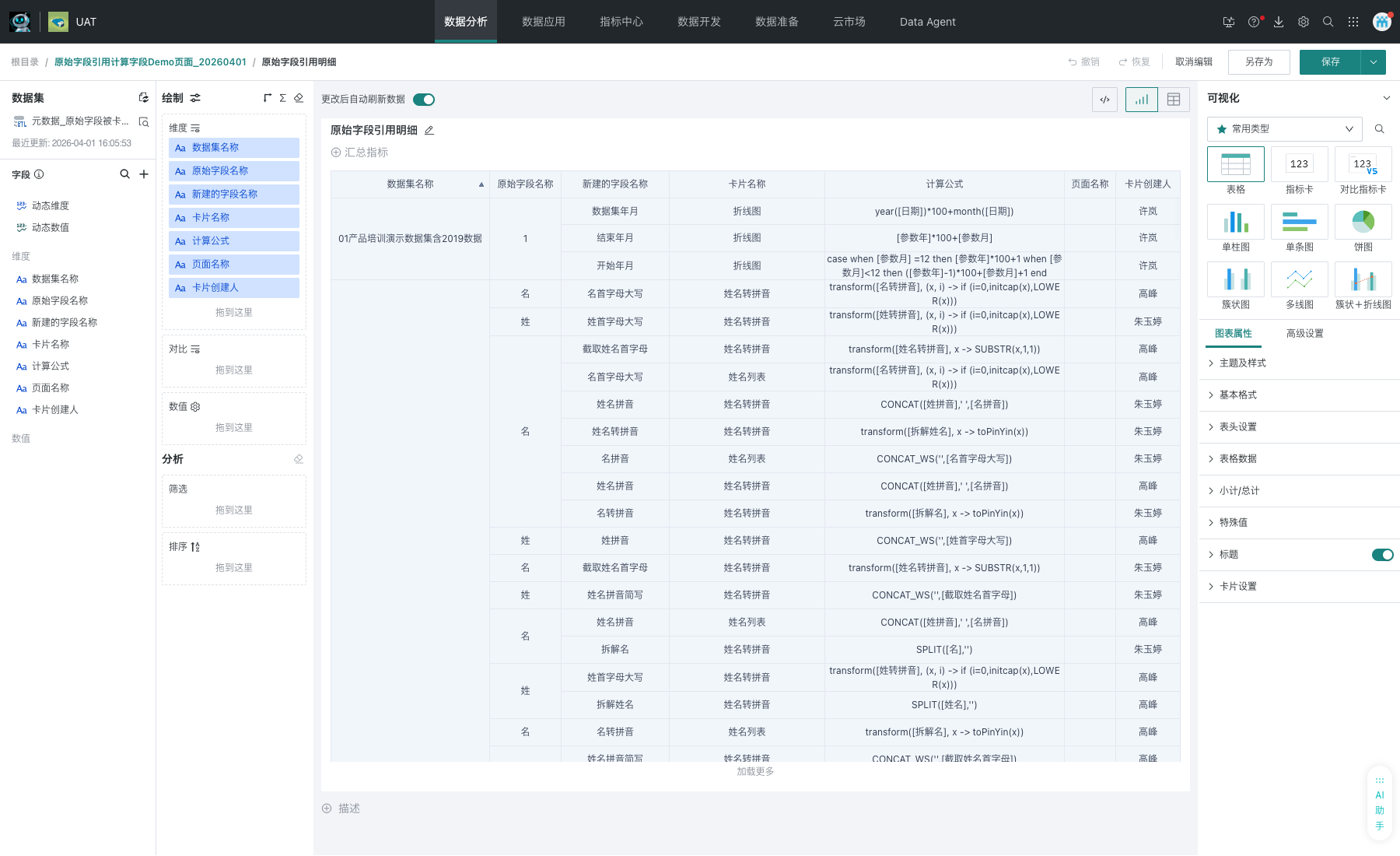
1、新建卡片并完成配置
基于 ETL 输出数据集,新建一个普通表格卡片,并将 数据集名称、原始字段名称、新建的字段名称、卡片名称、计算公式、页面名称、卡片创建人 放入维度区,同时对 数据集名称 设置升序排序。
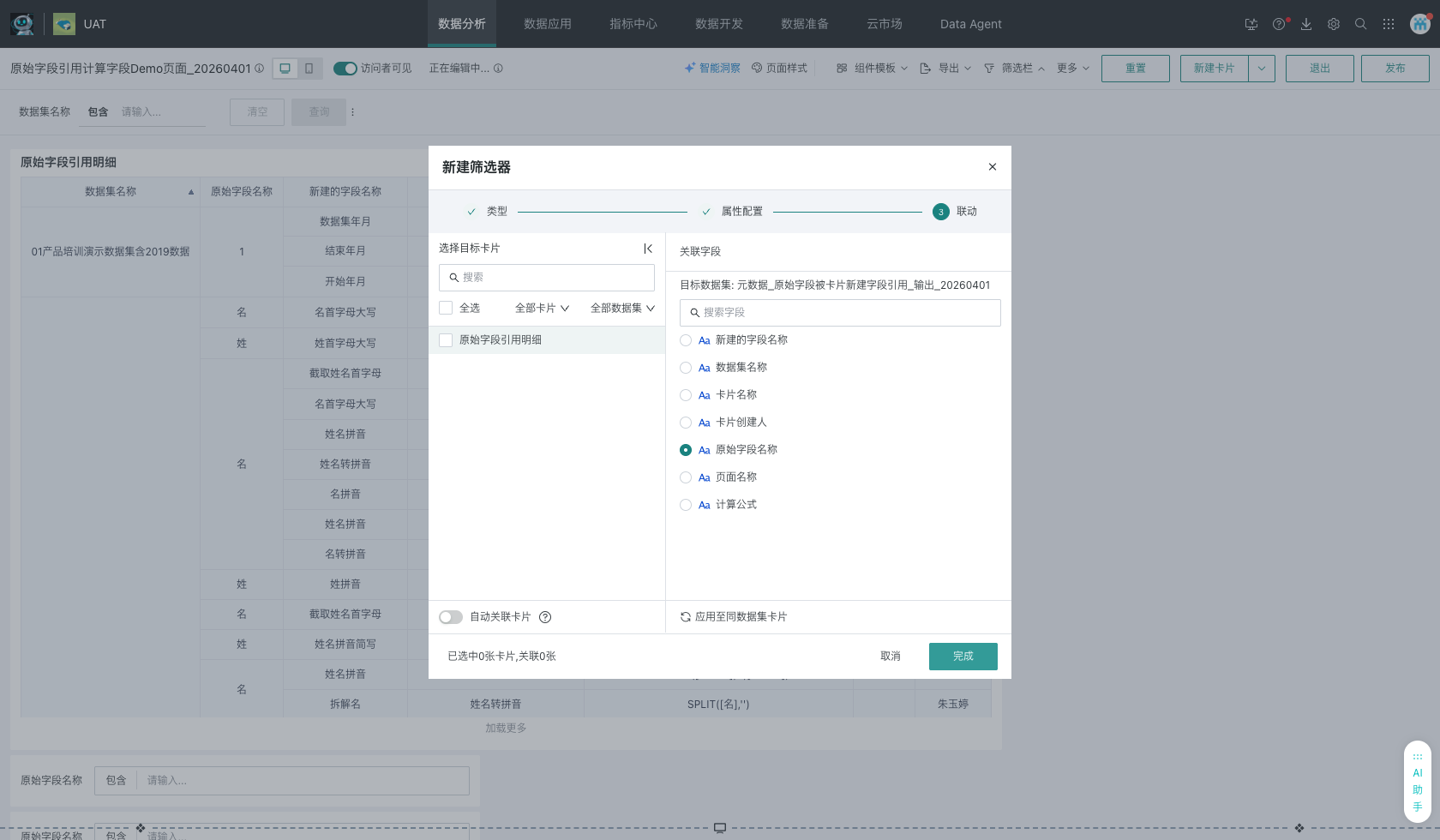
2、创建筛选器并完成联动
本次页面顶部共配置了两个输入型筛选器:数据集名称 与 原始字段名称。两个筛选器均直接联动到表格卡片,支持在页面上做快速查询。
筛选器字段选择示意:
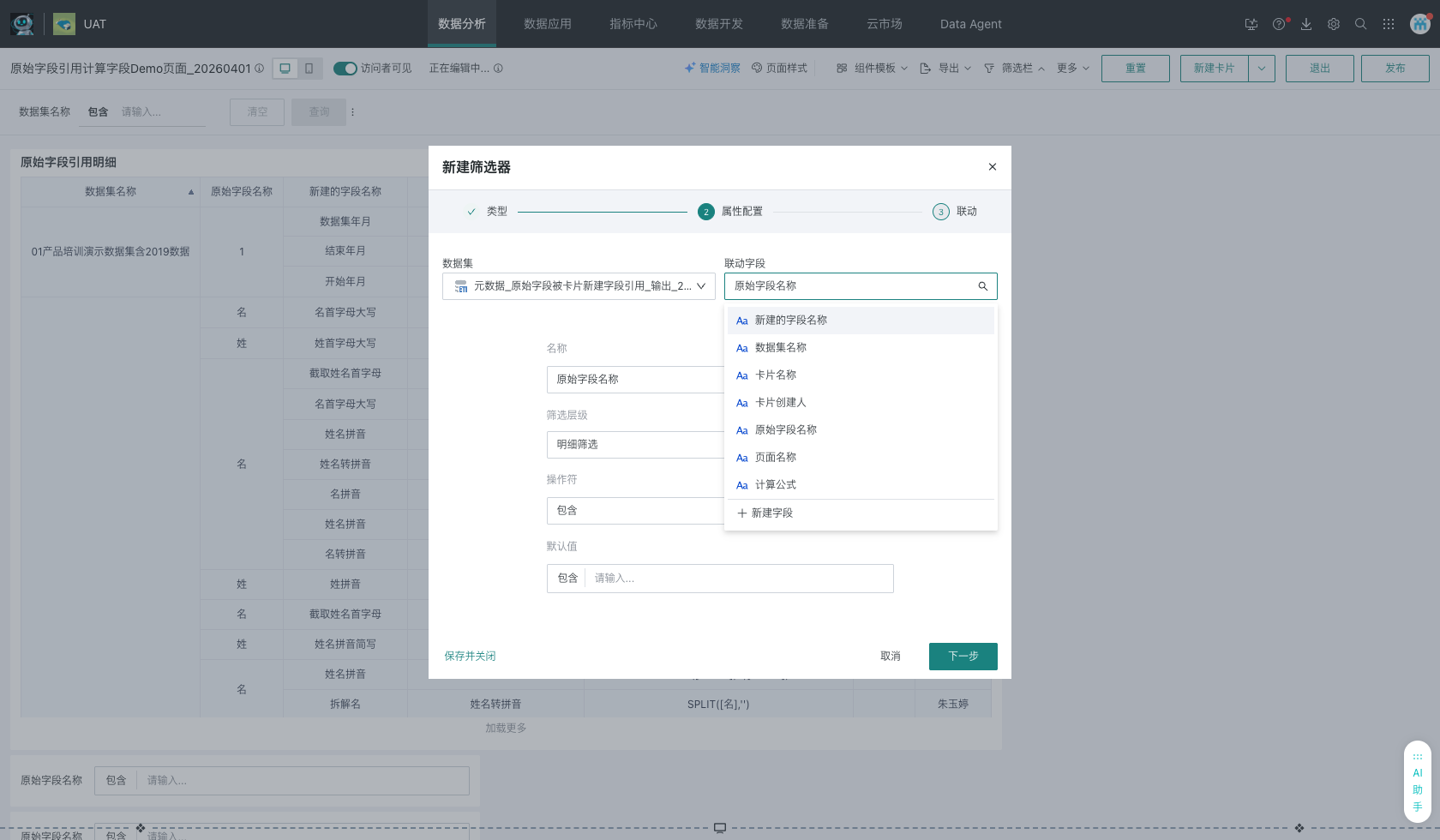
筛选器联动配置示意:
3、最终发布效果
最终页面支持按 数据集名称 和 原始字段名称 进行模糊筛选,表格中同时查看数据集、原始字段、新建字段、卡片、公式、页面和创建人信息,结果按 数据集名称 升序展示。
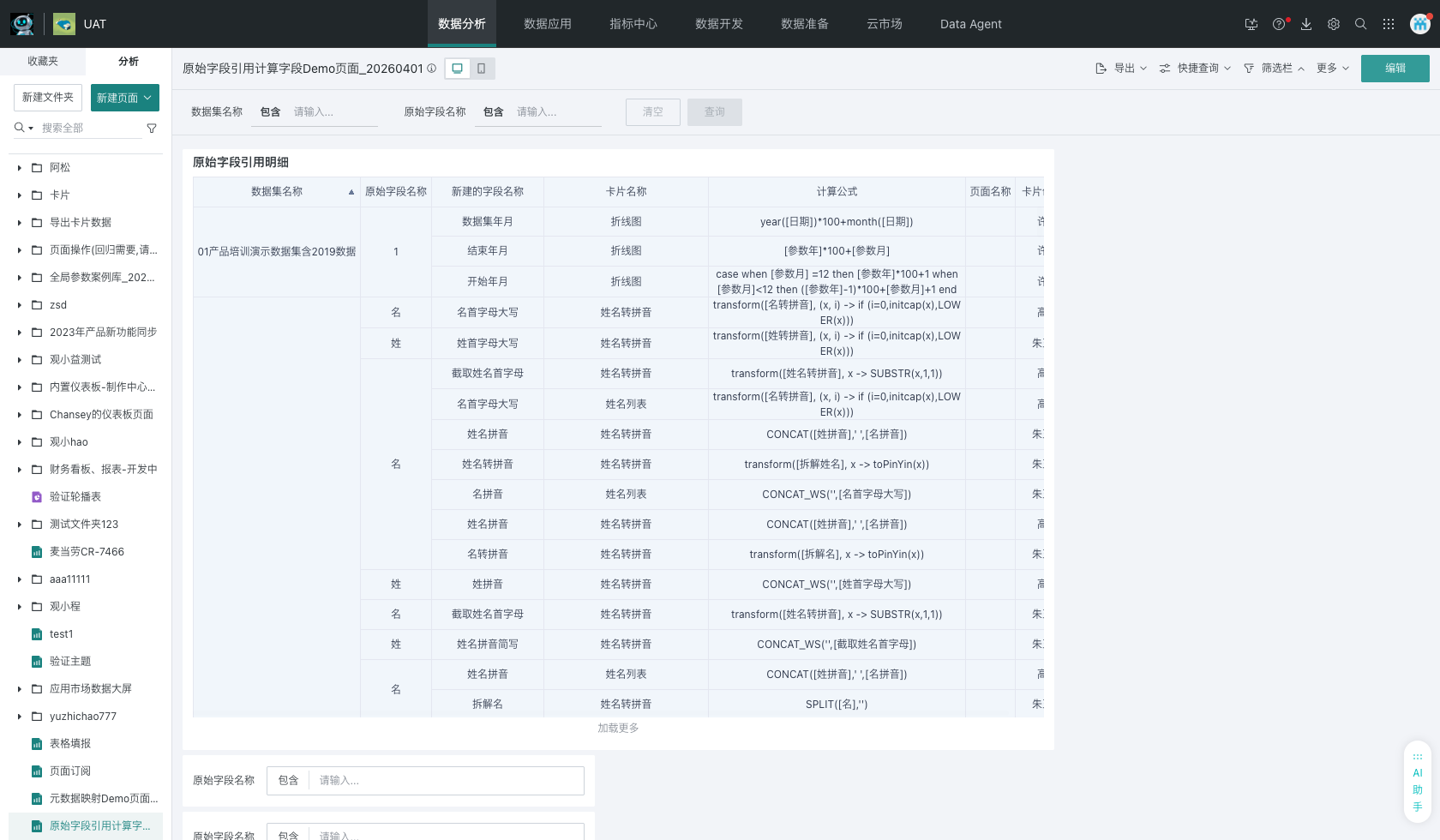
实践结果:
通过这次实践,我们沉淀出了一套可复用的“原始字段引用计算字段”排查链路:
- 用元数据库输入数据集统一读取
card / page_card_rel / page / user / field / data_source
- 在 ETL 中集中完成计算字段识别、公式拆解、原始字段匹配和页面信息补齐
- 输出标准明细表,供页面直接展示
- 通过双筛选器让使用者在页面上快速定位命中的引用关系
这套方案尤其适合字段下线评估、数据集治理、卡片公式排查、页面资产梳理和上线前字段依赖检查等场景。
总结:
这次实践把“如何判断数据库的原始字段,被哪些卡片新建计算字段引用了”整理成了一套可长期复用的链路:输入层保持元数据原样接入,ETL 层集中完成字段关系解析,页面层提供筛选查询入口,最终把复杂排查工作沉淀成一张可复用的查询页面。
如果后续继续扩展,这套方案还可以自然演进到两个方向:
- 增加目录、卡片类型、更新时间等治理维度,形成更完整的字段引用看板
- 扩展公式解析规则,覆盖更复杂的嵌套表达式和函数场景
| 





