背景有些业务分析场景,需要对维度进行分组,一个维度可能被多次分组,并且需要合并统计数值数据,然后在筛选器里也需要可以选择设置的分组进行查询,这个可以如何实现? 卡片自带的新建分组字段,虽然可以对字段进行分组,但是一个维度值只能在一个分组内,无法实现重复分组。下面介绍如何通过新建计算实现一个字段值重复分组的需求。
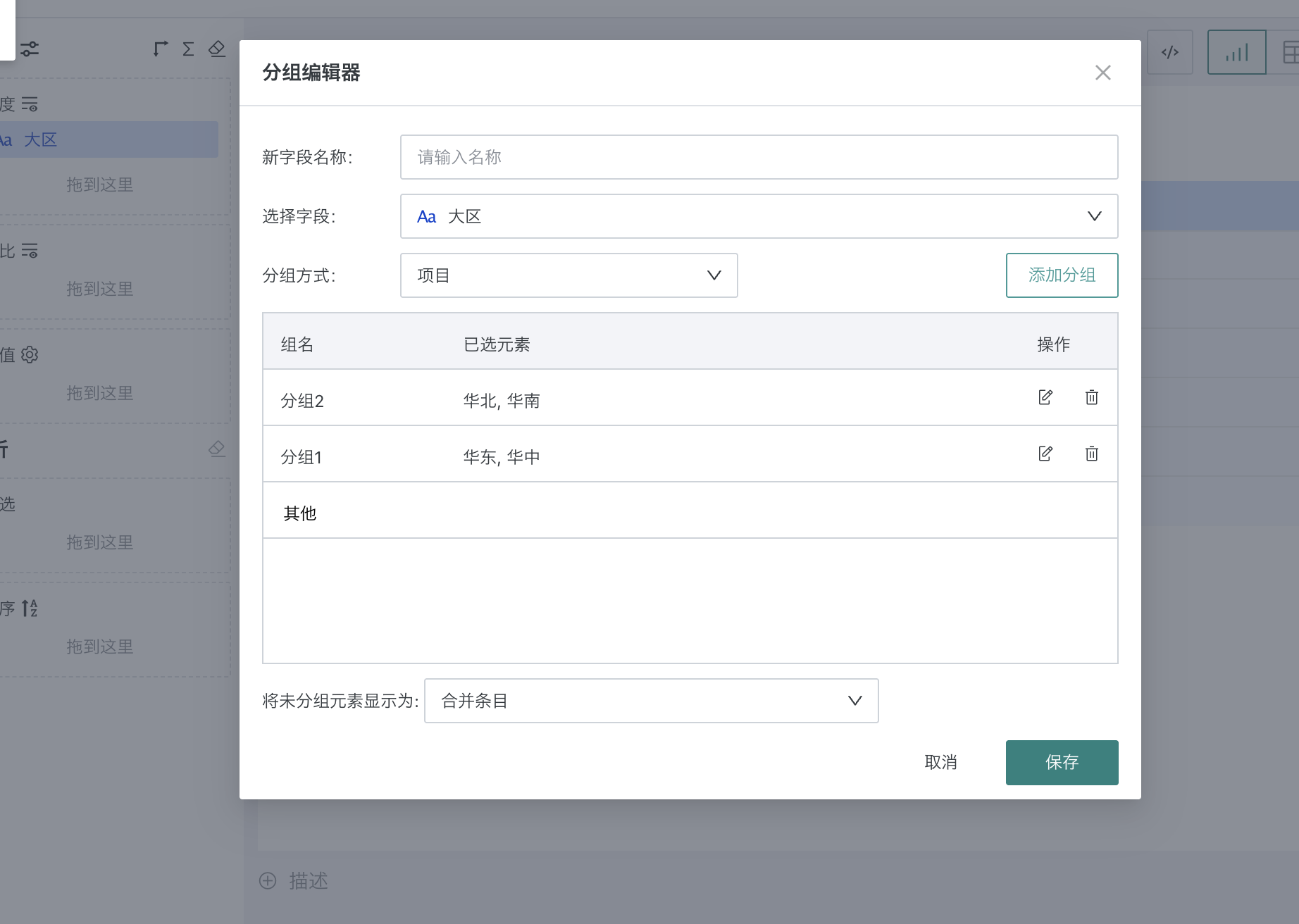
一、业务需求说明1. 原始字段字段: 取值示例:其它、华北、西南、华东、华中、华南 2. 自定义分组规则分组1:华东 + 华北 分组2:华东 + 华南
👉 特点:
3. 目标实现以下能力:
二、实现总体方案核心思路(三步): 1️⃣ 构造“分组数组” 2️⃣ explode 打平(多对多展开) 3️⃣ 按分组聚合统计
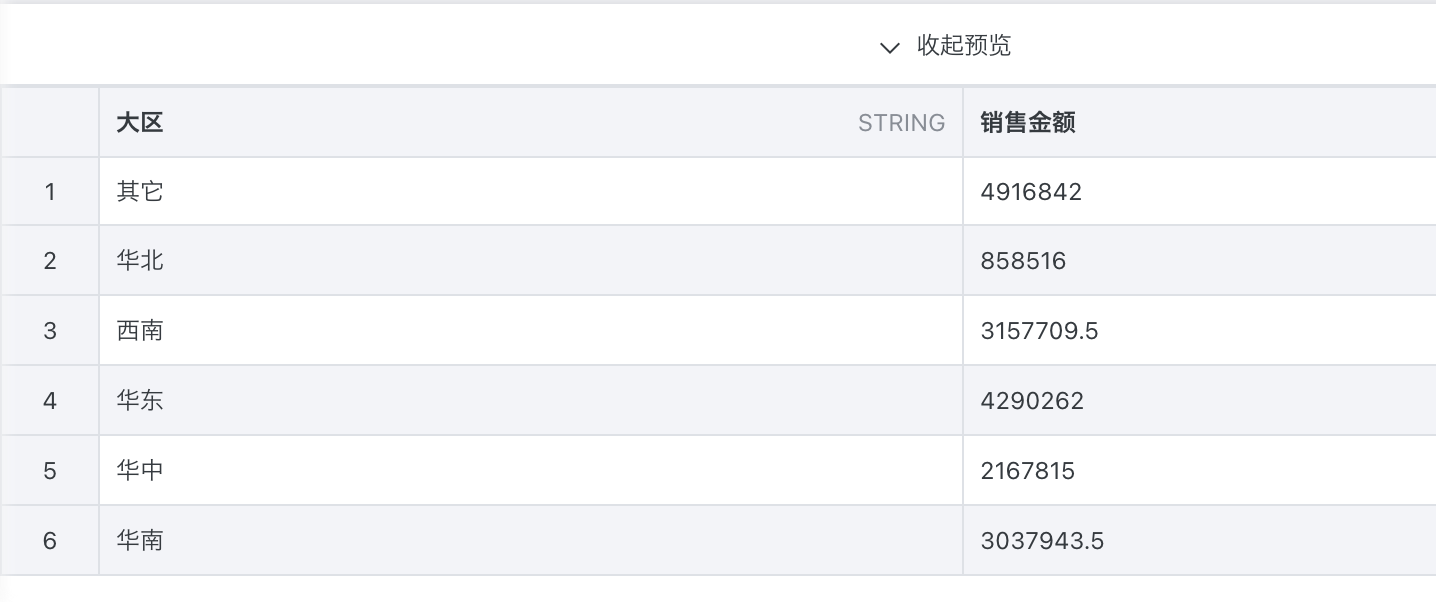
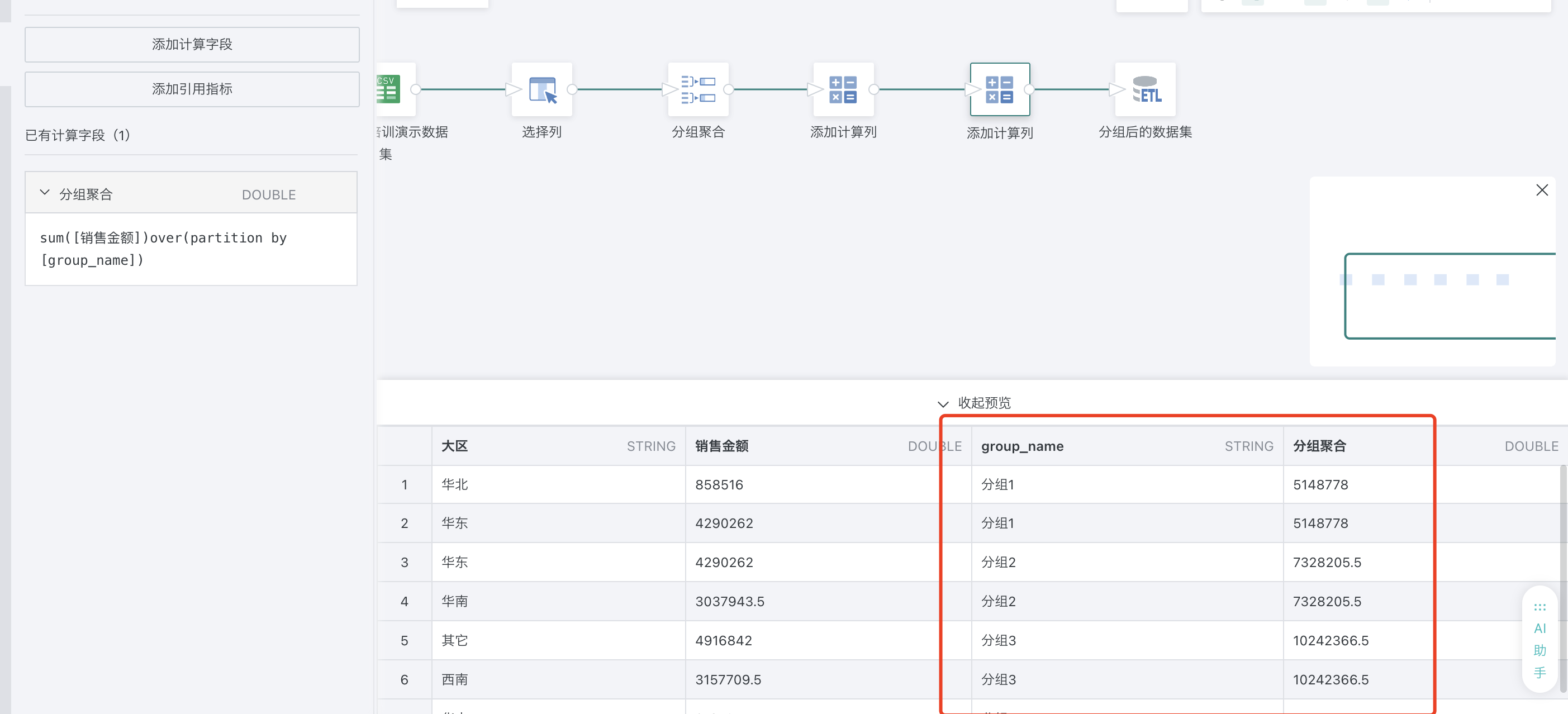
2、构造数组 array(...)3、过滤空值 filter(array, x -> x is not null)4、行展开 explode(...)5、分组聚合 sum() over (partition by ...)四、实操1、在etl中新建计算字段 group_name
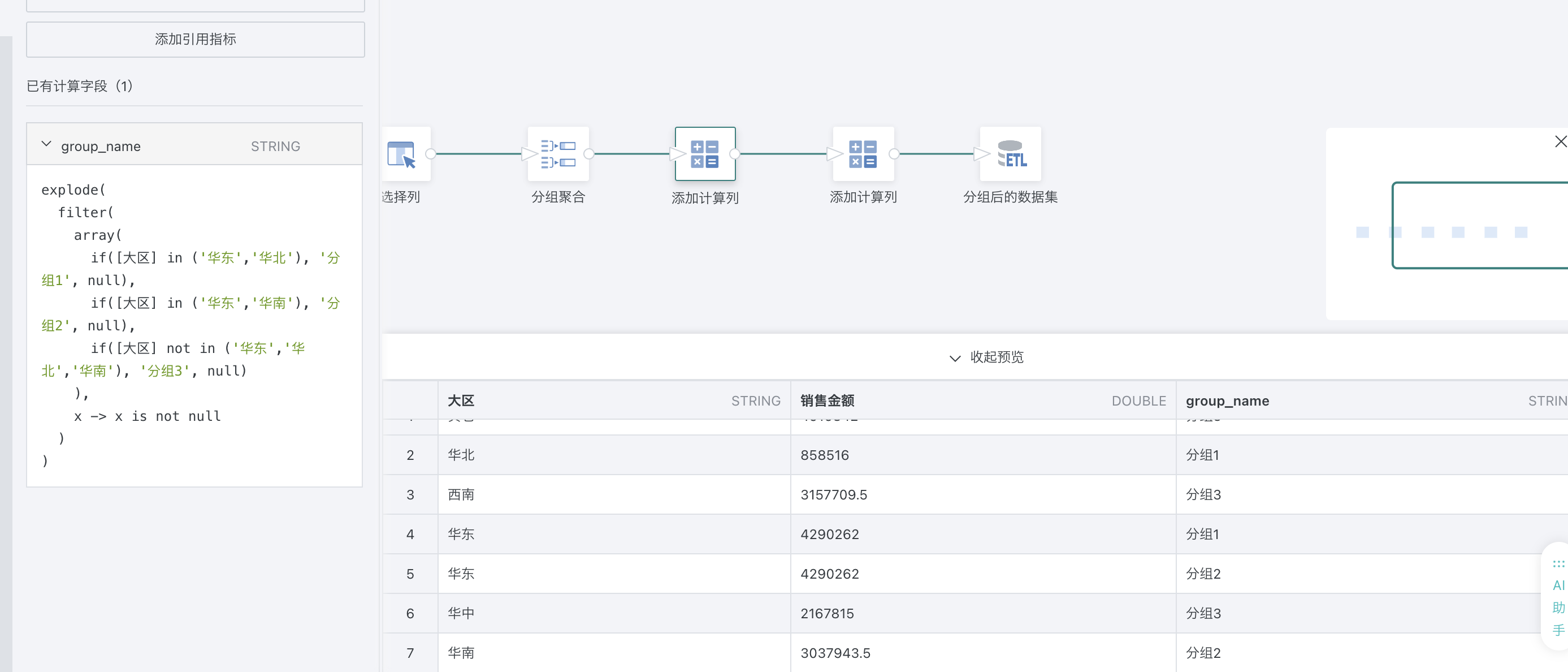 2、计算大区在各个分组内合并统计数值数据 sum([销售金额])over(partition by [group_name])
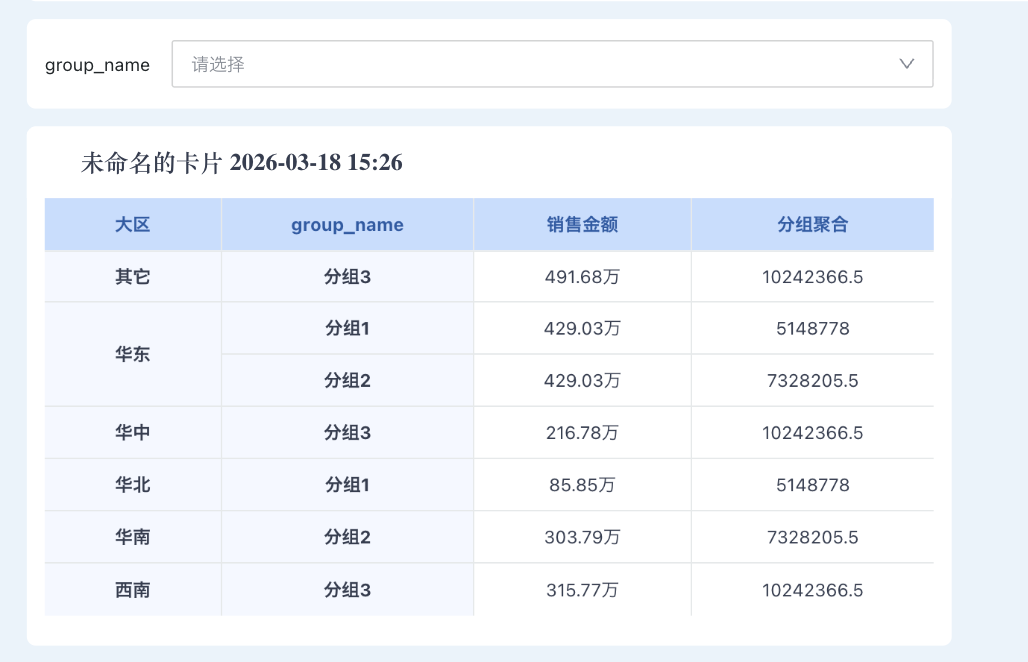
3、使用这个处理后数据集做卡片和筛选器,筛选字段 group_name,支持选择分组1 / 分组2 / 分组3,也可以用大区筛选,按实际业务需求选择。
本方案解决了: ✔ 多分组复用 核心一句话总结:用 array 构造分组 → explode 打平 → group by 聚合 |