
案例
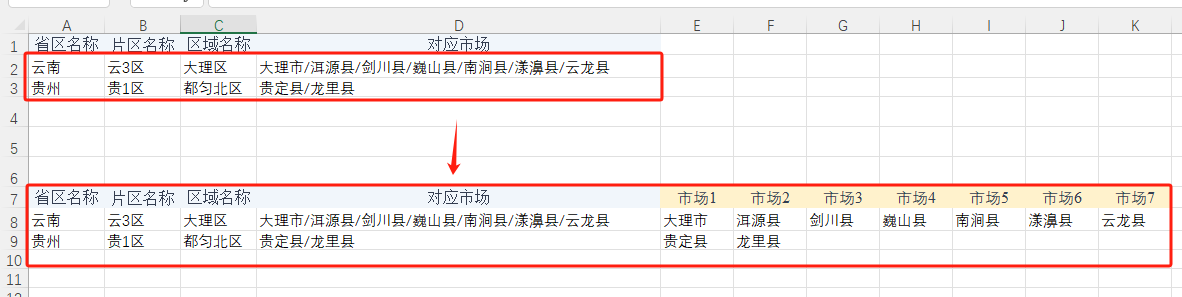
一个文本字段按“/”的分隔拆解成列,在etl中如何实现?如下图对应市场想要拆分成多列
实现:以下介绍2种方式,一种使用数组函数,一种使用etl行转列算子实现。
一、使用spark SQL数组函数实现
1、用分隔符拆分字符串,返回数组。split([对应市场],'/')


2、通过数组元素,分别获取不同的值,生成多个字段,按照最长元素个数取字段。没有值的元素结果会自动补充null值。
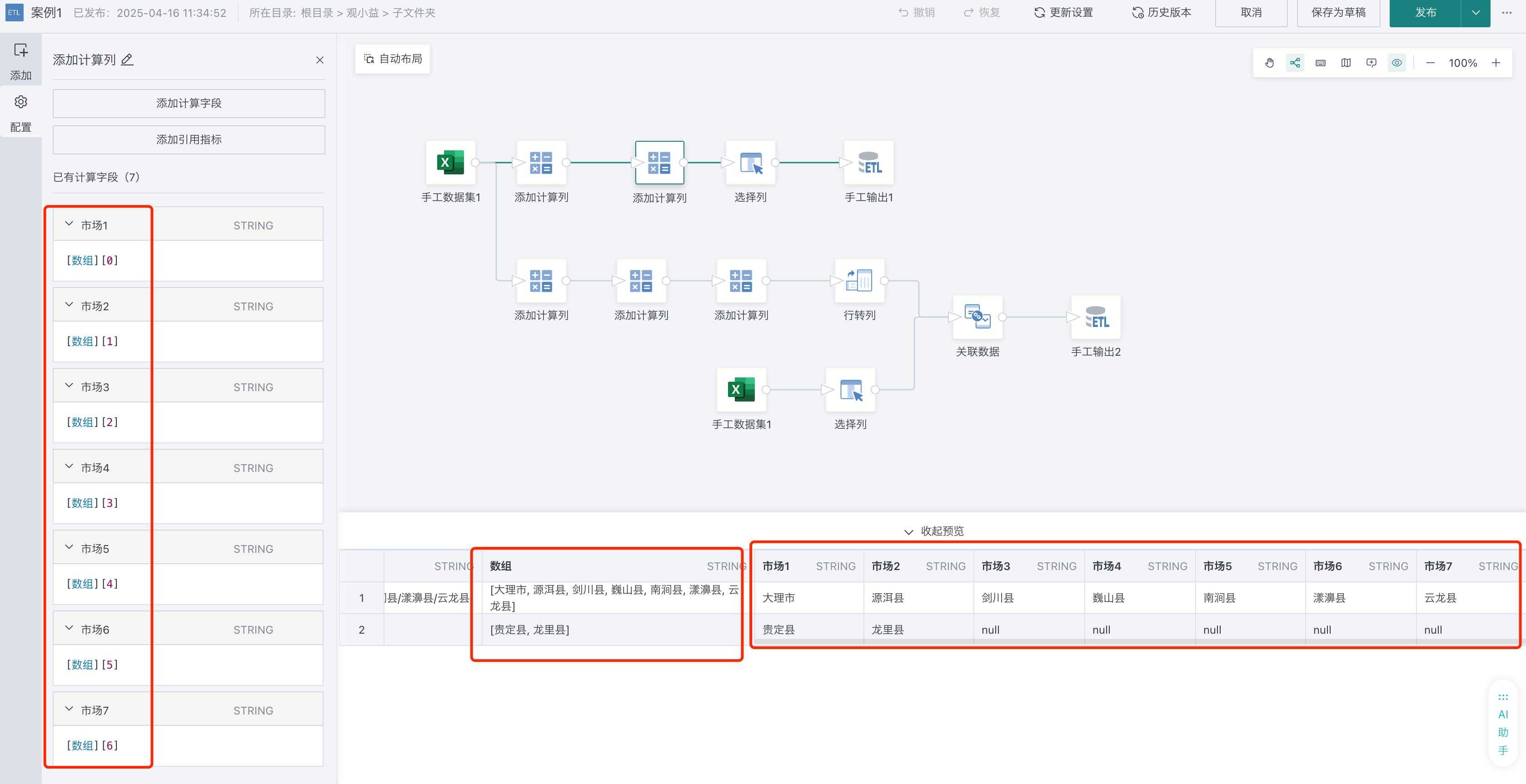
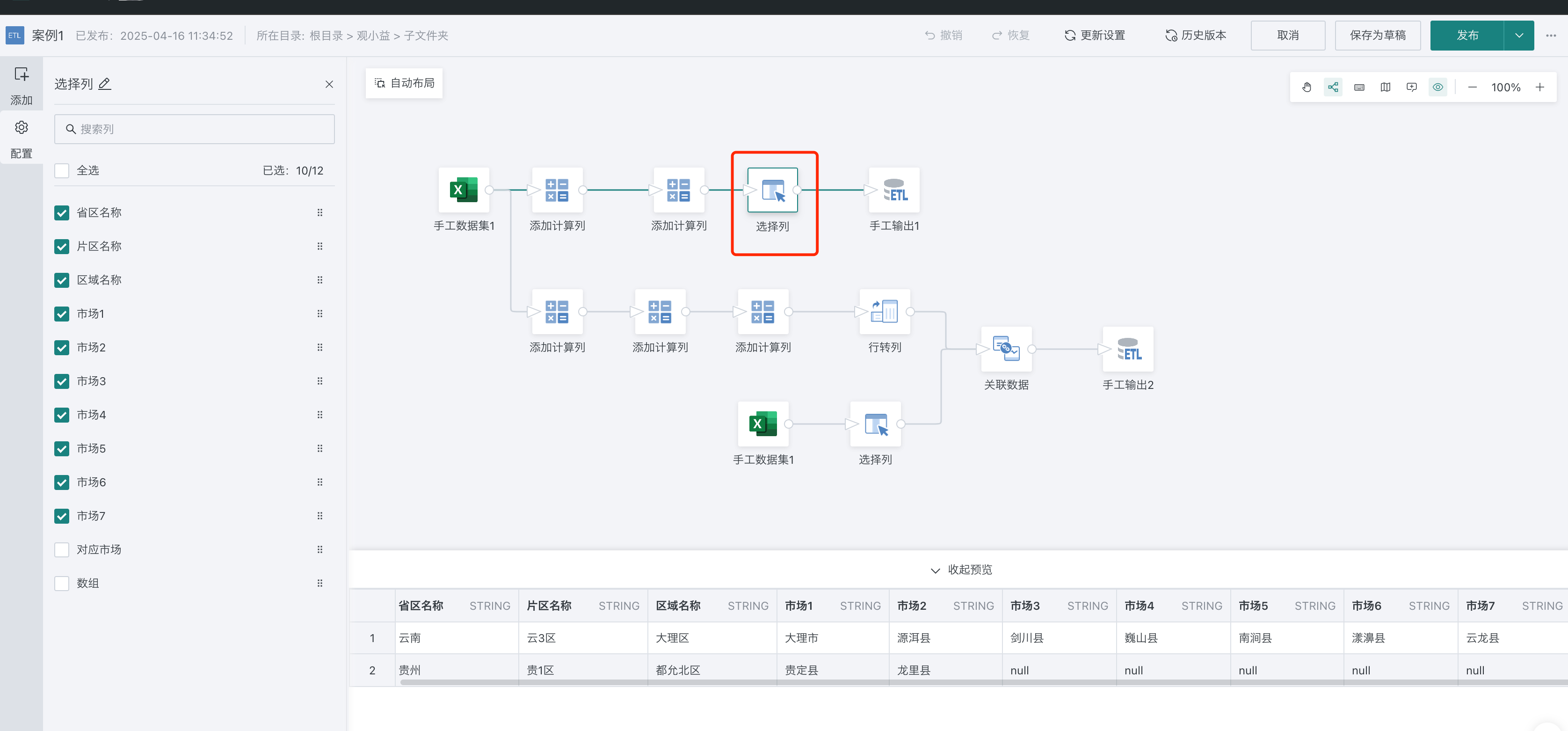
3、选择列,选择需要的字段输出数据集,做后续卡片分析
二、使用ETL行转列算子实现
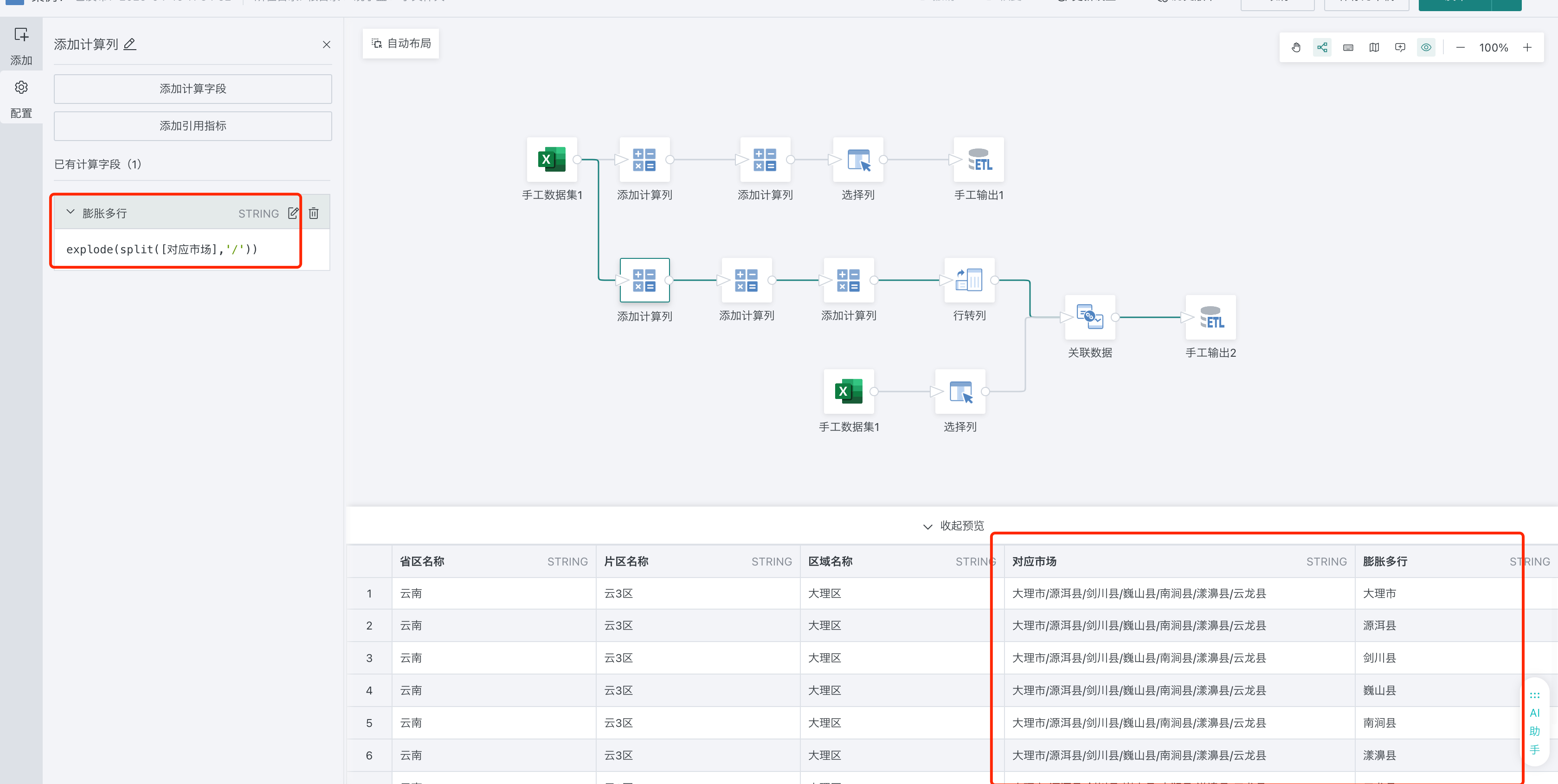
1、使用数组函数,把文本字段转为数组,再根据元素膨胀拆分成多行。explode(split([对应市场],'/'))

2、新建排序字段,按照数组元素位置给枚举值排序。为后续行列转所需列名字段做准备
row_number()over(partition by [省区名称] order by [膨胀多行])
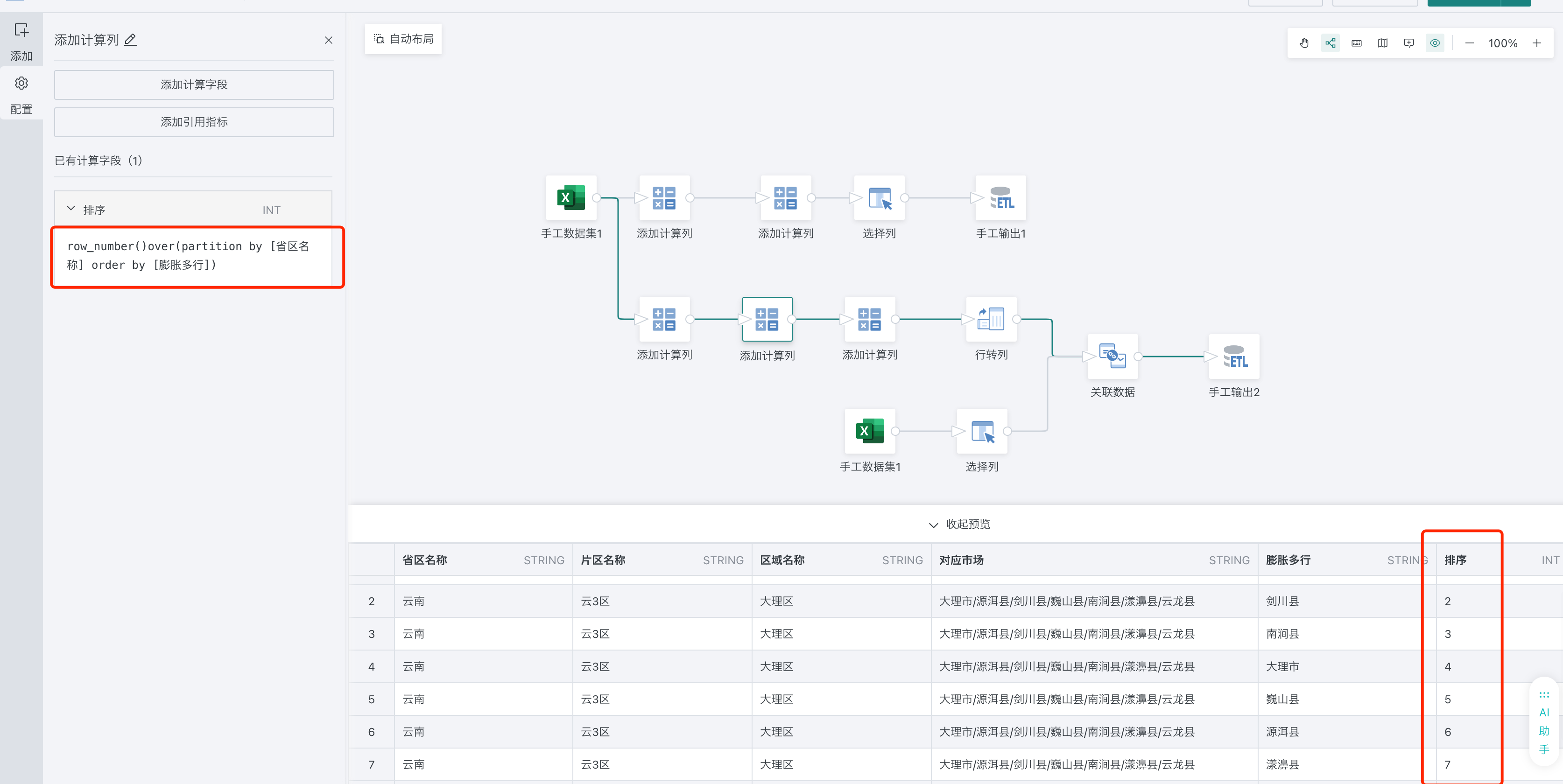
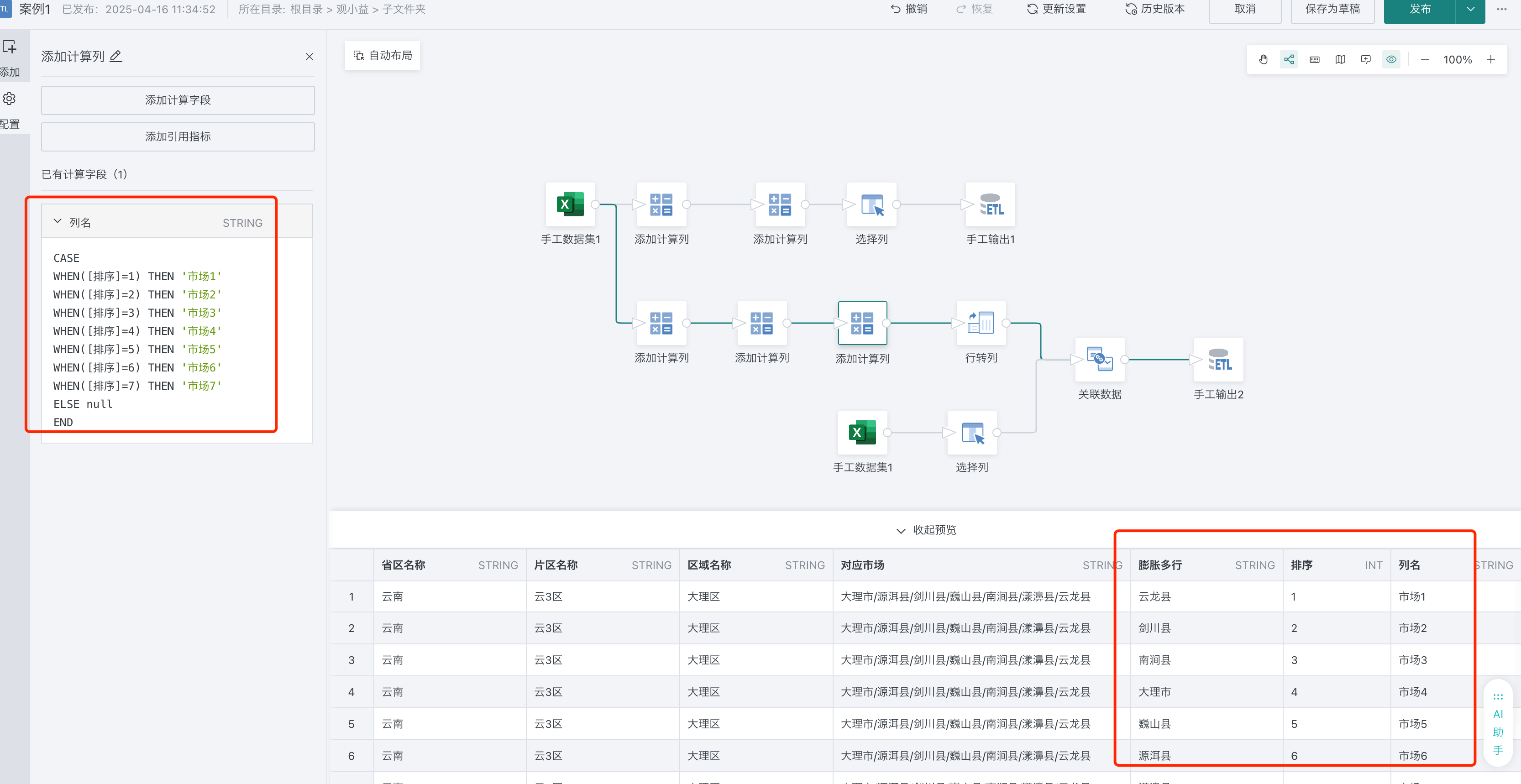
3、生成列名字段。
CASE
WHEN([排序]=1) THEN '市场1'
WHEN([排序]=2) THEN '市场2'
WHEN([排序]=3) THEN '市场3'
WHEN([排序]=4) THEN '市场4'
WHEN([排序]=5) THEN '市场5'
WHEN([排序]=6) THEN '市场6'
WHEN([排序]=7) THEN '市场7'
ELSE null
END
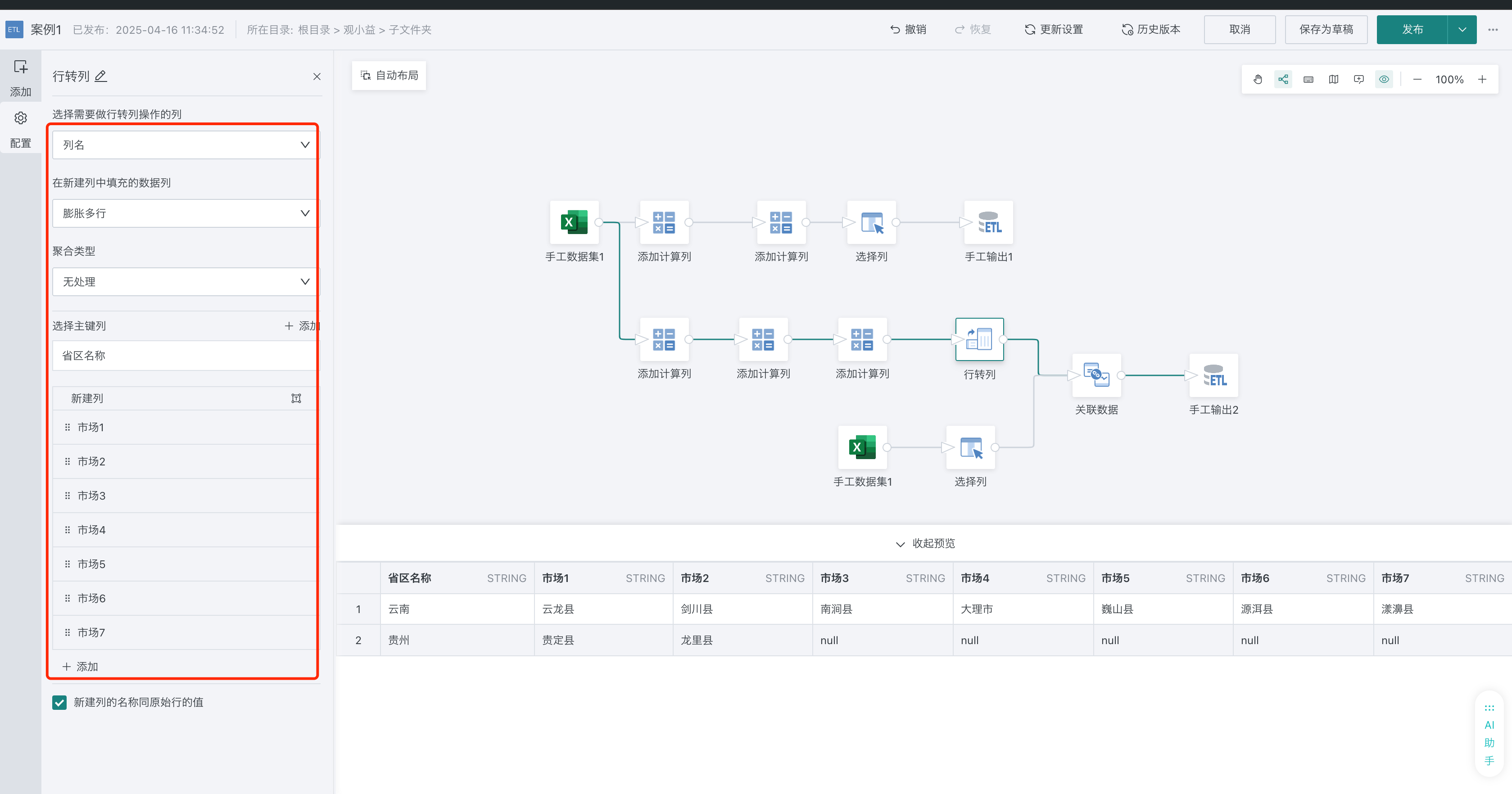
4、通过ETL行转列功能,把多行转多列
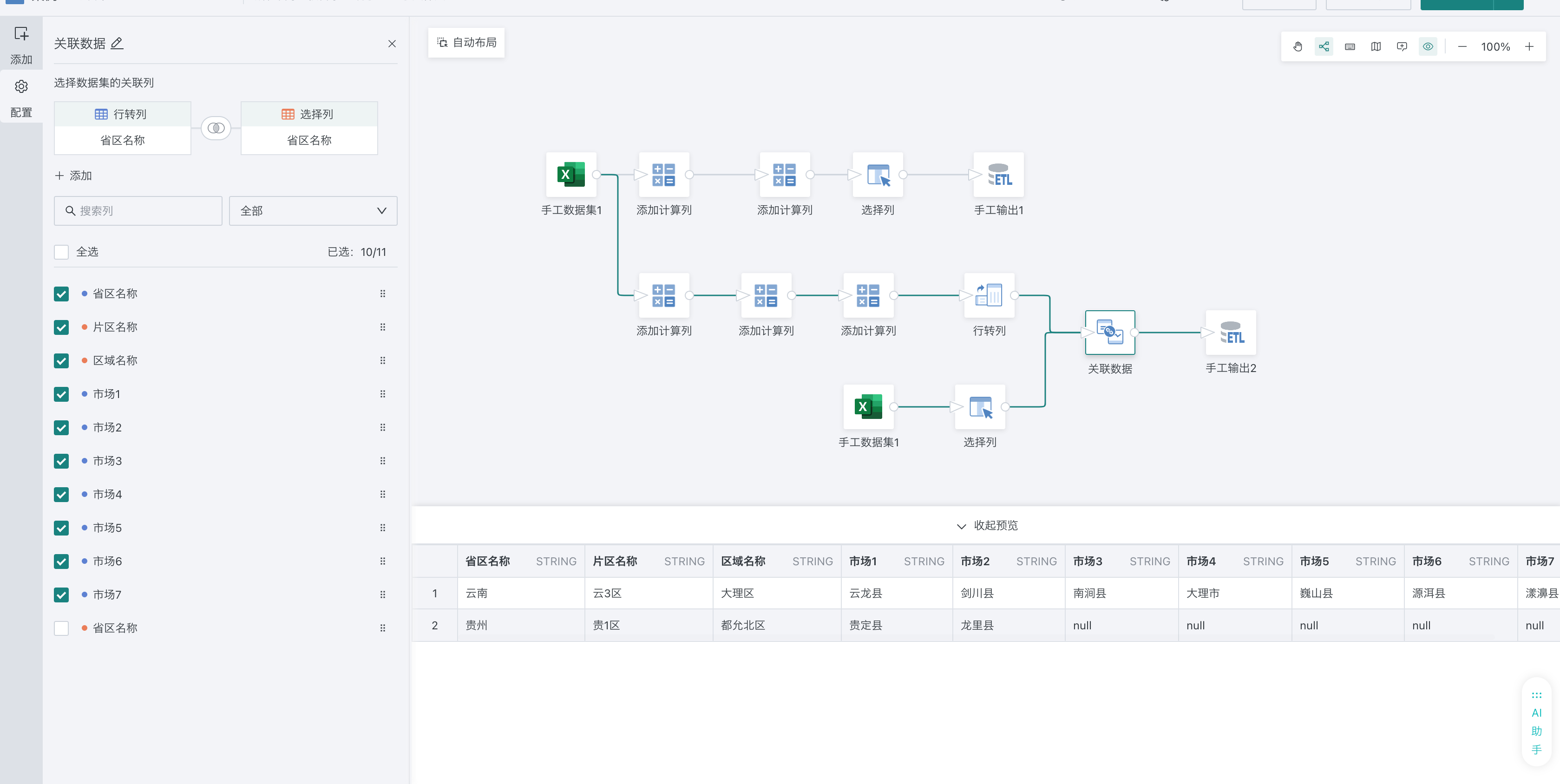
5、关联数据,把其他需要输出分析的字段关联到行转列结果上,输出数据集。
以上2种方案都可以实现所需结果,通过spark数组函数实现所需步骤更少,更简单。
注:行转列结果只保留了转换的几个字段,需要把其他字段关联回去,否则输出数据集会少字段。
行转列功能说明参考:https://docs.guandata.com/product/bi/574845011263225856
Spark日期函数及应用:https://docs.guandata.com/product/bi/428146642139480064





