【原因】:用户数据库使用的字符编码不是BI默认用的UTF-8编码,数据集更新后BI直接读取了这部分编码错误数据。以下为4种常见的中文字符乱码出现的场景:
**乱 码示例**| **产生原因**| **特点**
---|---|---
¹ÛÔ¶Êý¾Ý| 以ISO-8859-1读取GBK编码文字| 通常为带有上标的英文字母
��Զ����| 以UTF-8读取GBK编码文字| 通常为带有黑色方框的问号
瑙傝繙鏁版嵁| 以GBK读取UTF-8编码文字| 通常为生僻的繁体字
è§è¿æ°æ®| 以UTF-8读取ISO-8859-1编码文字| 包含有小写的西文字母和一些符号
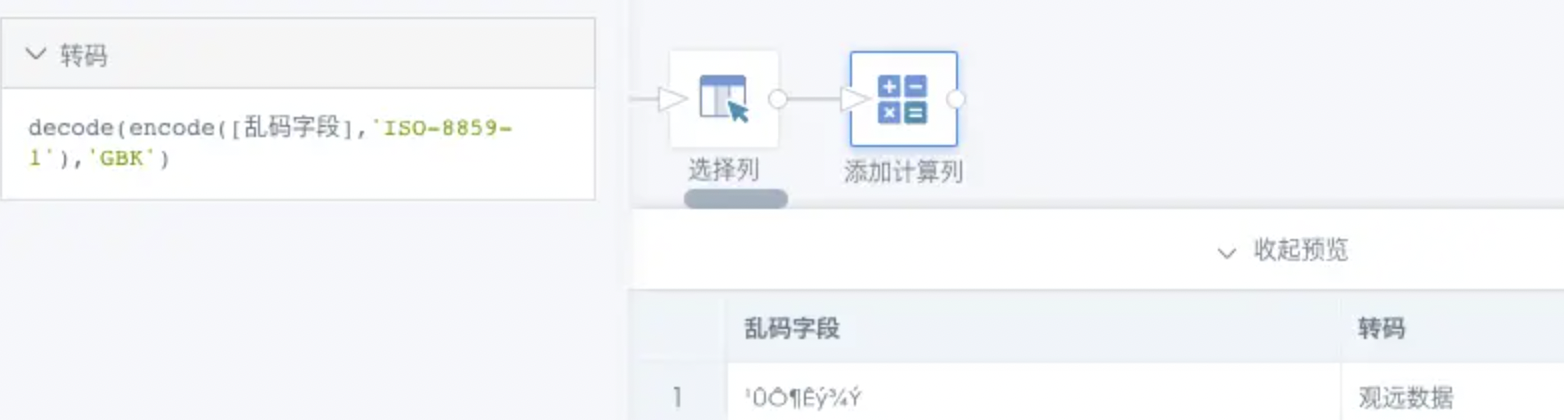
解决方案:修改源数据库的字符编码为UTF-8;如果定位和修改数据源比较困难,也可以在BI中把这部分数据重新编码:首先筛选出有问题的数据;定位到这部分数据是哪种错误的乱码;然后在新建字段中使用encode(decode([字段名], '类型1'), '类型2')来重新编码数据。
示例:以"¹ÛÔ¶Êý¾Ý"为例,它是以ISO-8859-1读取GBK编码的方式产生错误,那就需要把对应字段重新编码成ISO-8859-1的编码格式,然后再以GBK格式进行解码,那对应的新建字段类型就为decode(encode([字段名],'ISO-8859-1'),'GBK'),如图:
|